
Spring面试题
Spring面试题
Ioc
说一说什么是 IoC?
IoC(Inversion of Control)控制反转,不是什么技术,而是一种设计思想。将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
谁控制谁,控制什么?
传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对象的创建;谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
为何是反转,哪些方面反转了?
有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
传统程序设计下,都是主动去创建相关对象然后再组合起来:
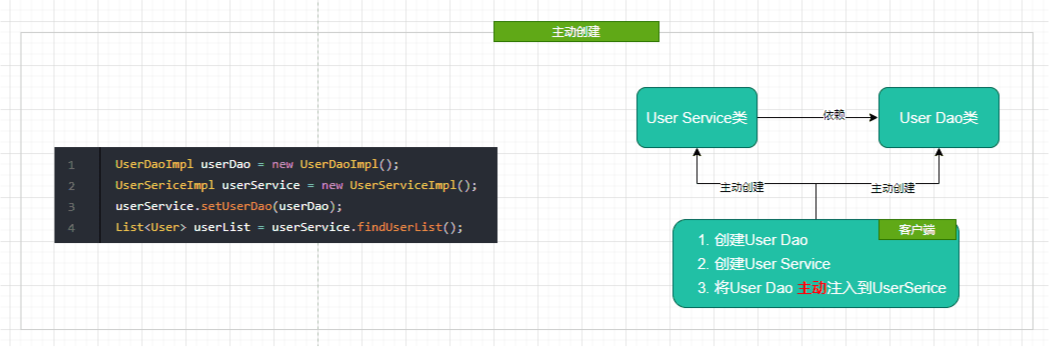
当有了IoC/DI的容器后,在客户端类中不再主动去创建这些对象了,如图
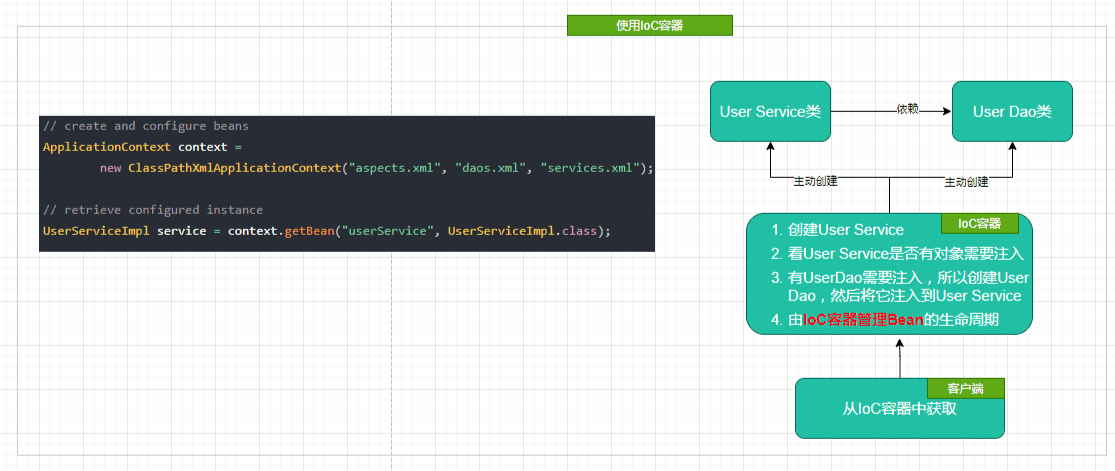
说一说什么是DI?
DI (Dependency Injection) 依赖注入,是实现 IOC 的具体方式,比如说利用注入机制(如构造器注入、Setter 注入或接口注入)将依赖传递给目标对象。
- 优点
- 在平时的 Java 开发中,如果我们要实现某一个功能,可能至少需要两个以上的对象来协助完成,在没有 Spring 之前,每个对象在需要它的合作对象时,需要自己 new 一个,比如说 A 要使用 B,A 就对 B 产生了依赖,也就是 A 和 B 之间存在了一种耦合关系。
- 有了 Spring 之后,就不一样了,创建 B 的工作交给了 Spring 来完成,Spring 创建好了 B 对象后就放到容器中,A 告诉 Spring 我需要 B,Spring 就从容器中取出 B 交给 A 来使用。
- 至于 B 是怎么来的,A 就不再关心了,Spring 容器想通过 new 创建 B 还是 new 创建 B,无所谓。
- 这就是 IoC 的好处,它降低了对象之间的耦合度,使得程序更加灵活,更加易于维护。
Spring的依赖注入有哪些实现方式?
- 构造函数注入:通过类的构造函数来注入依赖项。
- Setter 注入:通过类的 Setter 方法来注入依赖项。
- Field(字段) 注入:直接在类的字段上使用注解(如 @Autowired 或 @Resource)来注入依赖项。
@Autowired、@Resource 和 @Inject 的区别
| 特性 | @Autowired (Spring) |
@Resource (JSR-250) |
@Inject (JSR-330) |
|---|---|---|---|
| 来源规范 | Spring 专属 | Java EE 标准 (JSR-250) | Java DI 标准 (JSR-330) |
| 包路径 | org.springframework.beans.factory.annotation |
javax.annotation |
javax.inject |
| 默认注入方式 | 按类型 (byType) | 按名称 (byName) | 按类型 (byType) |
| 名称指定 | 需配合 @Qualifier |
直接使用 name 属性 |
需配合 @Named |
| 必需依赖 | 支持 required=false |
总是必需 | 总是必需 |
| 构造器注入 | ✅ 支持 | ❌ 不支持 | ✅ 支持 |
| 方法/字段 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
| 参数注入 | ✅ 支持 | ❌ 不支持 | ✅ 支持 |
| 自定义限定符 | ✅ 支持 | ❌ 不支持 | ✅ 支持 |
什么是 Spring Bean?
Bean 是指由 Spring 容器管理的对象,它的生命周期由容器控制,包括创建、初始化、使用和销毁。以通过三种方式声明:注解方式、XML 配置、Java 配置。
①、使用 @Component、@Service、@Repository、@Controller 等注解定义,主流。
②、基于 XML 配置,Spring Boot 项目已经不怎么用了。
③、使用 Java 配置类创建 Bean:
1 |
|
@Component 和 @Bean 的区别
@Component 是 Spring 提供的一个类级别注解,由 Spring 自动扫描并注册到 Spring 容器中。
@Bean 是一个方法级别的注解,用于显式地声明一个 Bean,当我们需要第三方库或者无法使用 @Component 注解类时,可以使用 @Bean 来将其实例注册到容器中。
说一下 Bean 的生命周期
实例化 → 属性注入 →(Aware 回调 → BeanPostProcessor 前置 → 初始化方法 → BeanPostProcessor 后置)→ 使用 →(销毁方法 → 资源释放)
- 实例化:Spring 首先使用构造方法或者工厂方法创建一个 Bean 的实例。在这个阶段,Bean 只是一个空的 Java 对象,还未设置任何属性。
- 属性注入:Spring 将配置文件中的属性值或依赖的 Bean 注入到该 Bean 中。这个过程称为依赖注入,确保 Bean 所需的所有依赖都被注入。
- 初始化:对注入属性后的 Bean 进行 “初始化”(如初始化连接、加载资源等),使其达到可用状态。
- Aware 接口回调(可选):
若 Bean 实现了Aware系列接口(如BeanNameAware、ApplicationContextAware),Spring 会回调接口方法,将容器相关信息传递给 Bean。BeanNameAware:获取当前 Bean 在容器中的名称(setBeanName);BeanFactoryAware:获取当前 Bean 所属的容器(setBeanFactory);ApplicationContextAware:获取 Spring 应用上下文(setApplicationContext)。
- BeanPostProcessor 前置处理(可选):
若容器中注册了BeanPostProcessor(Bean 后置处理器),会调用其postProcessBeforeInitialization方法,对 Bean 进行初始化前的自定义处理(如修改属性、增强功能)。
注:BeanPostProcessor对容器中所有 Bean 生效,是 Spring 扩展的核心机制之一。 - 初始化方法执行(可选):
执行用户定义的初始化逻辑,按以下优先级执行:@PostConstruct注解的方法(JSR-250 标准,在依赖注入完成后执行);- 实现
InitializingBean接口的afterPropertiesSet方法(Spring 内置接口,注入完成后回调); - 自定义
init-method(在 XML 中通过init-method指定,或@Bean(initMethod = "..."))。
- BeanPostProcessor 后置处理(可选):
调用BeanPostProcessor的postProcessAfterInitialization方法,对初始化后的 Bean 进行最终处理(如 AOP 代理就是通过此步骤生成代理对象)。
- Aware 接口回调(可选):
- 使用中:Bean 进入可用状态,供应用程序调用。此时 Bean 已完成初始化,可通过容器的
getBean方法获取,或被其他 Bean 依赖使用。 - 销毁:在容器关闭时,Spring 会调用 destroy 方法,释放 Bean 占用的资源(如关闭连接、释放缓存)。
Bean 的作用域有哪些?
在 Spring 中,Bean 默认是单例的,即在整个 Spring 容器中,每个 Bean 只有一个实例。
可以通过在配置中指定 scope 属性,将 Bean 改为多例(Prototype)模式,这样每次获取的都是新的实例。
在Spring配置文件中,可以通过标签的scope属性来指定Bean的作用域。例如:
1 | <bean id="myBean" class="com.example.MyBean" scope="singleton"/> |
基于Java的配置中,可以通过@Scope注解来指定Bean的作用域。例如:
1 |
|
Spring支持几种不同的作用域,以满足不同的应用场景需求。以下是一些主要的Bean作用域:
- Singleton(单例):在整个应用程序中只存在一个 Bean 实例。默认作用域,Spring 容器中只会创建一个 Bean 实例,并在容器的整个生命周期中共享该实例。
- Prototype(原型):每次请求时都会创建一个新的 Bean 实例。次从容器中获取该 Bean 时都会创建一个新实例,适用于状态非常瞬时的 Bean。
- Request(请求):每个 HTTP 请求都会创建一个新的 Bean 实例。仅在 Spring Web 应用程序中有效,每个 HTTP 请求都会创建一个新的 Bean 实例,适用于 Web 应用中需求局部性的 Bean。
- Session(会话):Session 范围内只会创建一个 Bean 实例。该 Bean 实例在用户会话范围内共享,仅在 Spring Web 应用程序中有效,适用于与用户会话相关的 Bean。
- Application:当前 ServletContext 中只存在一个 Bean 实例。仅在 Spring Web 应用程序中有效,该 Bean 实例在整个
- ServletContext 范围内共享,适用于应用程序范围内共享的 Bean。
- WebSocket(Web套接字):在 WebSocket 范围内只存在一个 Bean 实例。仅在支持 WebSocket 的应用程序中有效,该 Bean 实例在 WebSocket 会话范围内共享,适用于 WebSocket 会话范围内共享的 Bean。
Custom scopes(自定义作用域):Spring 允许开发者定义自定义的作用域,通过实现 Scope 接口来创建新的 Bean 作用域。
Spring中的单例Bean会存在线程安全问题吗?
在 Spring 中,单例 Bean 本身并不保证线程安全,其线程安全性取决于 Bean 的实现方式。单例 Bean 在容器中仅存在一个实例,当多个线程同时访问该实例时,若 Bean 包含可变状态(如成员变量),则可能出现线程安全问题;若 Bean 是无状态或不可变的,则线程安全。
单例 Bean 的线程安全问题:
可变状态的单例 Bean
若 Bean 中包含可被多个线程修改的成员变量(如计数器、集合),则存在线程安全隐患。
1
2
3
4
5
6
7
8
9
10
11
12
public class CounterService {
private int count = 0; // 可变状态,多线程访问可能冲突
public void increment() {
count++; // 非原子操作,存在竞态条件
}
public int getCount() {
return count;
}
}问题:多个线程同时调用
increment()时,由于count++不是原子操作,可能导致计数错误。有状态 Bean 的方法共享资源
若 Bean 的方法操作共享资源(如文件、数据库连接),且未进行同步控制,则可能出现线程安全问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
public class FileService {
private FileWriter writer; // 共享资源
public void init() throws IOException {
writer = new FileWriter("data.txt");
}
public void write(String data) throws IOException {
writer.write(data); // 多线程写入可能导致数据错乱
}
}问题:多个线程同时调用
write()可能导致文件内容混乱。
线程安全的单例 Bean 实现方式
无状态 Bean
Bean 不包含任何成员变量(仅提供方法逻辑),所有操作基于方法参数和局部变量。
1
2
3
4
5
6
public class CalculatorService {
public int add(int a, int b) {
return a + b; // 仅依赖方法参数,无共享状态
}
}线程安全原因:方法内的局部变量在每个线程的栈内存中独立存在,互不干扰。
不可变 Bean
Bean 的成员变量被声明为
final,且对象创建后状态不可变。1
2
3
4
5
6
7
8
9
10
11
12
13
public class ConfigService {
private final String apiKey;
public ConfigService( String apiKey) {
this.apiKey = apiKey; // 构造器注入后不可变
}
public String getApiKey() {
return apiKey;
}
}线程安全原因:不可变对象的状态无法被修改,多线程访问时不存在竞态条件。
同步机制
在有状态 Bean 中使用
synchronized、Lock或原子类(如AtomicInteger)保证线程安全。1
2
3
4
5
6
7
8
9
10
11
12
public class SafeCounterService {
private final AtomicInteger count = new AtomicInteger(0); // 原子类保证线程安全
public void increment() {
count.incrementAndGet(); // 原子操作
}
public int getCount() {
return count.get();
}
}线程安全原因:
AtomicInteger使用 CAS(Compare-and-Swap)保证原子性,避免锁竞争。1
2
3
4
5
6
7
8
9
10
11
12
13
public class CounterService {
private int count = 0; // 可变状态,多线程访问可能冲突
//使用 synchronized 确保线程安全
public synchronized void increment() {
count++; // 非原子操作,存在竞态条件
}
public int getCount() {
return count;
}
}使用 synchronized 确保线程安全
ThreadLocal 隔离线程状态
使用
ThreadLocal为每个线程提供独立的变量副本。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class RequestContextHolder {
private final ThreadLocal<String> requestId = new ThreadLocal<>();
public void setRequestId(String id) {
requestId.set(id);
}
public String getRequestId() {
return requestId.get();
}
public void clear() {
requestId.remove(); // 避免内存泄漏
}
}线程安全原因:每个线程独立维护自己的
ThreadLocal副本,互不干扰。改为 prototype 作用域
如果 Bean 确实需要维护状态,可以考虑将其改为 prototype 作用域,这样每次注入都会创建一个新的实例,避免了多线程共享同一个实例的问题。
1
2
3
4
5
6
7
8
9
// 每次注入都创建新实例
public class StatefulService {
private String state; // 现在每个实例都有独立状态
public void setState(String state) {
this.state = state;
}
}
FactoryBean 与 BeanFactory 的区别
- FactoryBean:它是一个工厂 Bean,实现了
FactoryBean接口,主要用于创建特定类型的 Bean 实例。 - BeanFactory:它是 Spring 容器的核心接口,负责管理和获取 Bean 实例,是容器的基础。
什么是循环依赖?
A 依赖 B,B 依赖 A,或者 C 依赖 C,就成了循环依赖。
1 | class ServiceA { |
原因很简单,AB 循环依赖,A 实例化的时候,发现依赖 B,创建 B 实例,创建 B 的时候发现需要 A,创建 A1 实例……无限套娃。。。。
Spring中的循环依赖如何处理?
Spring的解决方案:核心是三级缓存机制,通过提前暴露刚实例化(但未初始化)的 Bean 的早期引用(可能被包装成代理),并利用属性注入(Setter/Field) 来打破 Singleton Bean 的循环依赖。
graph TD
subgraph Spring容器
A[一级缓存] -->|完全初始化的Bean| singletonObjects
B[二级缓存] -->|早期暴露的Bean| earlySingletonObjects
C[三级缓存] -->|Bean工厂| singletonFactories
endsingletonObjects(一级缓存):- 存放内容: 完全初始化好的、可用的成品单例 Bean。
- 访问时机: 当需要获取一个 Bean 时,首先检查这里。
- 状态: Bean 已实例化、属性已填充、初始化方法(如
@PostConstruct、InitializingBean、init-method)已执行。
earlySingletonObjects(二级缓存):- 存放内容: 提前暴露的、早期的单例 Bean 引用。这些 Bean 已经实例化,但属性尚未填充(可能依赖其他 Bean),初始化方法也未执行。
- 作用: 解决循环依赖的关键。当一个 Bean 还在创建过程中(刚实例化完,还没填充属性),就提前把它放入这个缓存,供其他依赖它的 Bean 引用,从而打破循环。
- 状态: Bean 已实例化(调用了构造方法),但属性未填充,未初始化。
singletonFactories(三级缓存):- 存放内容: 单例对象工厂(
ObjectFactory)。每个单例 Bean 在实例化后(调用构造方法后),都会生成一个对应的ObjectFactory并放入此缓存。 ObjectFactory的作用: 当需要获取该 Bean 的早期引用时(比如在解决循环依赖时),会调用这个工厂的getObject()方法。这个方法最终会调用getEarlyBeanReference()。getEarlyBeanReference()的重要性:- 如果 Bean 不需要被 AOP 代理(如没有切面匹配它),这个方法直接返回原始的 Bean 实例。
- 如果 Bean 需要被 AOP 代理,这个方法会提前生成并返回代理对象。这是保证注入到其他 Bean 中的是代理对象(而不是原始对象)的关键,避免了后续注入不一致的问题。
- 存放内容: 单例对象工厂(
🔄 解决循环依赖的流程(以 ServiceA 和 ServiceB 为例)
- 开始创建
ServiceA:- 容器发现需要创建
ServiceA。 - 调用
ServiceA的构造方法,实例化ServiceA对象(此时serviceB属性还是null)。 - 将创建
ServiceA的ObjectFactory放入 **三级缓存 (singletonFactories)**。
- 容器发现需要创建
- 填充
ServiceA的属性:- 容器准备为
serviceB属性赋值。 - 发现需要注入
ServiceB,于是去获取ServiceB。
- 容器准备为
- 开始创建
ServiceB:- 容器发现需要创建
ServiceB。 - 调用
ServiceB的构造方法,实例化ServiceB对象(此时serviceA属性还是null)。 - 将创建
ServiceB的ObjectFactory放入 **三级缓存 (singletonFactories)**。
- 容器发现需要创建
- 填充
ServiceB的属性:- 容器准备为
serviceA属性赋值。 - 发现需要注入
ServiceA,于是去获取ServiceA。
- 容器准备为
- 获取
ServiceA(关键步骤):- 在
singletonObjects(一级缓存) 中未找到完全初始化的ServiceA。 - 在
earlySingletonObjects(二级缓存) 中未找到ServiceA的早期引用。 - 在
singletonFactories(三级缓存) 中找到了ServiceA的ObjectFactory。 - 调用
ObjectFactory.getObject()-> 实际调用getEarlyBeanReference()。- 如果
ServiceA需要 AOP 代理,则在此刻生成代理对象并返回。 - 如果不需要,则返回原始
ServiceA对象。
- 如果
- 将这个(可能是代理的)早期对象放入 **二级缓存 (
earlySingletonObjects)**,并从三级缓存中移除对应的ObjectFactory。 - 将这个早期对象注入到
ServiceB的serviceA属性中。至此,ServiceB的属性填充完成。
- 在
- 完成
ServiceB的初始化:- 执行
ServiceB的初始化方法(@PostConstruct等)。 - 将完全初始化好的
ServiceB放入 **一级缓存 (singletonObjects)**,并从二级和三级缓存中移除。
- 执行
- 回到填充
ServiceA的属性:- 容器现在获取到了完全初始化好的
ServiceB(它已经在步骤 6 中被放入一级缓存)。 - 将
ServiceB注入到ServiceA的serviceB属性中。至此,ServiceA的属性填充完成。
- 容器现在获取到了完全初始化好的
- 完成
ServiceA的初始化:- 执行
ServiceA的初始化方法(@PostConstruct等)。 - 将完全初始化好的
ServiceA放入 **一级缓存 (singletonObjects)**,并从二级缓存中移除(它之前在步骤 5 被放入了二级缓存)。
- 执行
✅ 至此,循环依赖成功解决! ServiceA 持有完整的 ServiceB,ServiceB 持有完整的 ServiceA(或 ServiceA 的代理对象)。
解决条件与限制
Spring只能解决特定条件下的循环依赖:
- 必须是单例Bean:原型(prototype)作用域的Bean无法解决
- 不能是构造器注入:仅支持属性注入或setter注入
- 需要Spring管理:不能是new创建的对象
当遇到构造器注入的循环依赖时,Spring会直接抛出BeanCurrentlyInCreationException异常。
为什么要二级缓存, 一级缓存能实现吗?
理论上可以的, 只要在设计一级缓存的过程中能准确的标识当前 bean 是处于完成状态还是半成品状态即可; 但是如果通过二级缓存, 可以简化代码开发, 并且能提高每次的判断执行效率, 所以引入二级缓存
为什么用三级缓存解决循环依赖问题?用二级缓存不行吗?
如果不引入三级缓存的话会造成一下问题, 如果 B 通过二级缓存将 A 的值进行填充了,那么 B 中 A 的对象就是 A 的原始 bean 对象; 因为 bean 的生命周期中 bean 的字段填充是发生在初始化之前的, 所以当 A 进行后续操作中被代理了功能得到增强了, 那么 B 中的 A 字段是无法被更新和感知的; 所以引入三级缓存的概念, 如果 A 被代理了, 那么在 B 在进行赋值的时候就可以将代理提前。
举个栗子
假设只有两级缓存(仅保留一级和二级缓存)
- 实例化 BeanA → 直接放入二级缓存(
earlySingletonObjects) - 填充 BeanA 属性时发现需要 BeanB
- 实例化 BeanB → 直接放入二级缓存
- 填充 BeanB 属性时发现需要 BeanA → 从二级缓存取出 BeanA 的原始对象
- 将 BeanA 注入 BeanB
- 完成 BeanB 初始化 → 移入一级缓存
- 继续填充 BeanA → 注入已完成的 BeanB
- 完成 BeanA 初始化 → 移入一级缓存
表面看似乎可行?但遇到 AOP 代理时会暴露致命缺陷!
如果BeanA需要被动态代理(比如加了
@Transactional),如果没有三级缓存,当填充BeanB的属性BeanA时,拿到的是 A 的原始对象。Spring 需要在初始化阶段之后生成代理对象A ;会导致:sequenceDiagram participant C as Spring容器 participant A as BeanA原始对象 participant P as BeanA代理对象 C->>A: 1. 实例化BeanA(原始对象) C->>C: 2. 将原始BeanA存入二级缓存 C->>A: 3. 填充属性(需要BeanB)... ## 创建BeanB并注入原始BeanA ... C->>A: 4. 执行BeanA初始化 C->>P: 5. 【问题点】此时才生成代理对象 C->>C: 6. 将代理对象放入一级缓存代理对象失效:循环依赖时,其他 BeanB 注入的是原始 BeanA 实例,而非代理对象,AOP 增强逻辑无法生效。
代理时机错误:代理对象应在 BeanA初始化完成后生成,若提前存入二级缓存,会破坏初始化流程。
- 实例化 BeanA → 直接放入二级缓存(
三级缓存的解决方案:
三级缓存存储 ObjectFactory,其 getObject() 方法可延迟生成代理对象(调用 getEarlyBeanReference() 方法)。当发生循环依赖时,通过工厂生成代理对象并放入二级缓存,确保其他 Bean 注入的是代理后的实例。
@Lazy 能解决循环依赖吗?
@Lazy的作用原理@Lazy注解的核心作用是延迟加载 Bean 的实例化过程,即当真正需要用到该Bean的时候才去初始化。当应用于循环依赖场景时:- 延迟依赖注入:将依赖对象包装为
Proxy(代理对象),在实际使用时才创建真实实例。 - 打破初始化死锁:避免两个 Bean 在初始化阶段互相等待对方实例化完成。
- 延迟依赖注入:将依赖对象包装为
@Lazy能解决的场景构造器注入的循环依赖(Spring 默认无法解决)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class A {
private final B b;
public A( B b) { // 使用@Lazy延迟加载B
this.b = b;
}
}
public class B {
private final A a;
public B( A a) { // 使用@Lazy延迟加载A
this.a = a;
}
}原理:注入时实际保存的是B的代理对象(而非真实实例),A可以顺利完成初始化。当A首次使用B时,才会触发B的真实实例化。
单例与原型 Bean 的循环依赖
1
2
3
4
5
6
7
8
9
10
11
12
public class A {
private B b;
}
public class B {
private A a;
}问题:原型 Bean 不支持三级缓存,默认无法解决循环依赖。
解决方法
1
2
3
4
5
6
7
8
9
10
11
12
13
public class A {
private B b;
}
public class B {
private A a;
}
能解决:通过延迟加载和代理对象,
@Lazy可以解决构造器注入的循环依赖,以及非单例 Bean 的循环依赖。不能解决:如果循环依赖的 Bean 在初始化阶段就需要真实依赖对象(而非代理),
@Lazy无法解决问题,此时必须重构代码。
AOP
说说什么是 AOP?
AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,AOP 就是把一些业务逻辑中的相同代码抽取到一个独立的模块中,让业务逻辑更加清爽。简单的把 AOP 理解为贯穿于方法之中,在方法执行前、执行时、执行后、返回值后、异常后要执行的操作。
它的核心是 “将程序中跨多个模块的通用功能(比如日志记录、事务管理、权限校验等)从业务逻辑中抽离出来,单独维护”,实现 “业务逻辑与通用功能的解耦”。
核心概念
切面(Aspect)
被抽离出来的通用功能模块,包含 “要增强的逻辑” 和 “在哪里增强”。可以认为是切入点(Pointcut)+通知(Advice)。
示例:日志记录、权限校验、事务管理等。
@Aspect public class LoggingAspect { @Before("execution(* com.example.service.*.*(..))") public void logBefore() { System.out.println("Logging before method execution"); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- **连接点(Join Point)**
- 程序执行过程中**可插入切面的点**,例如方法调用、异常处理等,AOP允许在这些点上插入切面逻辑。在 Spring AOP 中,仅支持方法级别的连接点。
- **示例**:某个 Service 方法被调用时、Controller 返回响应前。
- **切入点(Pointcut)**
- 定义 “**哪些连接点需要被增强**”,筛选出真正需要应用切面的位置。通常使用 @Pointcut 注解来定义切点表达式。
- 举个栗子:
```java
// 匹配所有UserService类的方法
@Pointcut("execution(* com.example.service.UserService.*(..))")
// 匹配所有带@Log注解的方法
@Pointcut("@annotation(com.example.annotation.Log)")
通知(Advice)
指拦截到目标对象的连接点之后要做的事情,也可以称作切面中具体的增强逻辑。
- 前置通知(Before):目标方法执行前。
- 后置通知(After):目标方法执行后(无论是否异常)。
- 返回通知(AfterReturning):目标方法正常返回后。
- 异常通知(AfterThrowing):目标方法抛出异常时。
- 环绕通知(Around):包裹目标方法,可自定义执行时机。
目标对象(Target)
就是被代理的对象,或者叫被切面增强的对象(即包含核心业务逻辑的类)。
代理(Proxy)
AOP 通过动态代理技术生成 “增强后的对象”。
- 两种代理方式:
- JDK 动态代理:基于接口,代理对象实现目标接口。
- CGLIB 代理:基于继承,代理对象继承目标类。
- 两种代理方式:
织入(Weaving)
将切面逻辑插入目标对象,生成代理对象的过程。
- 发生时机:
- 编译时:如 AspectJ 编译时织入。
- 类加载时:如使用 LoadTimeWeaver。
- 运行时:如 Spring AOP 的动态代理。
AOP的使用场景有哪些?
AOP 的使用场景有很多,比如说日志记录、事务管理、权限控制、性能监控等。
日志记录
添加 Maven 依赖
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>定义日志注解(用于标记需要记录的方法)
1
2
3
4
5
6
7
8
9
10import java.lang.annotation.*;
public Loggable {
String value() default ""; // 自定义操作描述
boolean recordParams() default true; // 是否记录参数
boolean recordResult() default true; // 是否记录返回值
}实现日志切面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.util.Arrays;
public class LoggingAspect {
private static final Logger logger = LoggerFactory.getLogger(LoggingAspect.class);
// 切入点:所有带有自定义@Loggable注解的方法为切点
public void loggableMethods() {}
// 环绕通知(最灵活,可控制方法执行)
public Object logAround(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Loggable loggable = signature.getMethod().getAnnotation(Loggable.class);
// 方法开始日志
long startTime = System.currentTimeMillis();
logMethodStart(joinPoint, loggable);
try {
// 执行目标方法
Object result = joinPoint.proceed();
// 方法结束日志
long executionTime = System.currentTimeMillis() - startTime;
logMethodEnd(joinPoint, loggable, result, executionTime);
return result;
} catch (Exception e) {
// 异常日志
long executionTime = System.currentTimeMillis() - startTime;
logException(joinPoint, loggable, e, executionTime);
throw e;
}
}
private void logMethodStart(JoinPoint joinPoint, Loggable loggable) {
String methodName = joinPoint.getSignature().toShortString();
String description = loggable.value().isEmpty() ? methodName : loggable.value();
StringBuilder logMessage = new StringBuilder();
logMessage.append("▶️ 开始执行: ").append(description);
if (loggable.recordParams()) {
Object[] args = joinPoint.getArgs();
logMessage.append(" | 参数: ").append(Arrays.toString(args));
}
logger.info(logMessage.toString());
}
private void logMethodEnd(JoinPoint joinPoint, Loggable loggable, Object result, long executionTime) {
String methodName = joinPoint.getSignature().toShortString();
String description = loggable.value().isEmpty() ? methodName : loggable.value();
StringBuilder logMessage = new StringBuilder();
logMessage.append("✅ 执行完成: ").append(description)
.append(" | 耗时: ").append(executionTime).append("ms");
if (loggable.recordResult() && result != null) {
logMessage.append(" | 结果: ").append(result.toString());
}
logger.info(logMessage.toString());
}
private void logException(JoinPoint joinPoint, Loggable loggable, Exception e, long executionTime) {
String methodName = joinPoint.getSignature().toShortString();
String description = loggable.value().isEmpty() ? methodName : loggable.value();
String errorMsg = String.format("❌ 执行异常: %s | 耗时: %dms | 异常: %s - %s",
description, executionTime, e.getClass().getSimpleName(), e.getMessage());
logger.error(errorMsg, e);
}
}在使用的地方加上自定义注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class UserService {
public User createUser(String name, String email) {
// 业务逻辑
return new User(name, email);
}
public List<User> getUsers() {
// 业务逻辑
return Arrays.asList(new User("Alice", "alice@example.com"));
}
public void deleteUser(Long id) {
// 业务逻辑
if (id <= 0) throw new IllegalArgumentException("无效的用户ID");
}
}日志输出示例
正常执行日志
1
2▶️ 开始执行: 创建用户 | 参数: [John Doe, john@example.com]
✅ 执行完成: 创建用户 | 耗时: 42ms | 结果: User{name='John Doe', email='john@example.com'}异常执行日志
1
2▶️ 开始执行: 删除用户 | 参数: [-1]
❌ 执行异常: 删除用户 | 耗时: 5ms | 异常: IllegalArgumentException - 无效的用户ID
事务管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52package com.example.aop.transaction;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.AfterThrowing;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* 事务切面,使用AOP控制事务边界
*/
public class TransactionAspect {
//负责事务的底层操作,包括获取连接、开启事务、提交 / 回滚事务等。
private TransactionManager transactionManager;
// 定义切入点:匹配所有Service包下的方法
public void serviceMethods() {}
// 环绕通知:控制事务的开启、提交和回滚
public Object around(JoinPoint joinPoint) throws Throwable {
try {
// 开启事务
transactionManager.beginTransaction();
// 执行目标方法
Object result = joinPoint.proceed();
// 提交事务
transactionManager.commit();
return result;
} catch (Exception e) {
// 回滚事务
transactionManager.rollback();
throw e;
}
}
// 异常通知:当方法抛出异常时回滚事务
public void afterThrowing(JoinPoint joinPoint, Exception ex) {
transactionManager.rollback();
}
}
说说 JDK 动态代理和 CGLIB 代理?
AOP 是通过动态代理实现的,代理方式有两种:JDK 动态代理和 CGLIB 代理。
Spring AOP 默认优先使用 JDK 动态代理,当目标类 没有实现接口 时,会自动切换为 CGLIB 代理。如果希望强制使用 CGLIB 代理(即使目标类有接口),可以通过配置开启(如 @EnableAspectJAutoProxy(proxyTargetClass = true))。
| 特性 | JDK 动态代理 | CGLIB 动态代理 |
|---|---|---|
| 依赖接口 | 必须实现接口 | 无需接口,基于继承 |
| 代理方式 | 生成实现接口的代理类 | 生成继承目标类的子类 |
| 性能 | 创建快,调用慢(反射) | 创建慢,调用快(字节码) |
| 适用场景 | 接口导向的框架(如 Spring AOP) | 无接口的类(如 Spring 的 @Service) |
说说 Spring AOP 和 AspectJ 的 区别?
- 定位不同
- Spring AOP:Spring 框架的轻量级 AOP 实现,依赖 Spring IoC 容器,仅支持方法级别的增强。
- AspectJ:独立的、功能完整的 AOP 框架,支持 方法调用、字段访问、构造函数、静态初始化 等各种连接点(Join Point),提供更强大的切面能力。
- 实现原理不同
- Spring AOP:运行时基于代理(Proxy),通过 JDK 动态代理(接口代理)或 CGLIB(类代理)生成代理对象,在方法调用时插入切面逻辑。
- AspectJ:编译期或类加载期织入字节码,直接修改目标类的字节码,将切面逻辑嵌入到目标方法中,无需代理对象。
- 功能范围不同
- Spring AOP:仅支持 5 种通知类型(Before、After、AfterReturning、AfterThrowing、Around)和简单的切入点表达式(如
execution、@annotation)。 - AspectJ:支持完整的 AspectJ 语法,包括 引介增强(@DeclareParents)、各种切入点类型(如
call、get、set)及更灵活的切面实例化模型(如perthis、pertarget)。
- Spring AOP:仅支持 5 种通知类型(Before、After、AfterReturning、AfterThrowing、Around)和简单的切入点表达式(如
- 性能不同
- Spring AOP:运行时代理生成有一定开销,但多次调用后趋于稳定,适合大多数业务场景。
- AspectJ:编译期织入无运行时开销,性能更优,适合对性能敏感的高频调用场景。
- 应用场景不同
- Spring AOP:适用于 Spring 项目中的简单切面需求(如日志、事务、权限校验),与 Spring 生态无缝集成。
- AspectJ:适用于 复杂切面需求(如拦截字段访问、静态方法)或 非 Spring 项目(如独立 Java 应用、Android 开发)。
Spring MVC
什么是Spring MVC?
Spring MVC 是 Spring 框架的一个模块,用于构建基于 Java 的 Web 应用程序。它遵循 MVC(Model-View-Controller)设计模式,将 Web 应用划分为三个核心组件:模型(Model)、视图(View) 和 控制器(Controller),以实现关注点分离,提高代码可维护性和可测试性。
Spring MVC的核心组件
DispatcherServlet(前端控制器):作为请求的统一入口,接收所有 HTTP 请求并分发给相应的处理组件进行处理,并根据处理结果将响应返回给客户端。
HandlerMapping(处理器映射器):确定哪个
Controller(或Handler) 应该处理传入的请求。它维护了一个请求 URL(或请求方法、参数等条件)到具体 Controller 方法的映射关系。DispatcherServlet 查询 HandlerMapping 来找到匹配当前请求的 Handler(通常是一个 Controller 的方法)和可选的拦截器链。常见的实现如 RequestMappingHandlerMapping (基于 @RequestMapping 注解)。
HandlerAdapter(处理器适配器):负责实际调用找到的
Handler(通常是Controller方法) 来处理请求,并且适配不同类型的处理器。。因为
Handler的实现方式可以多种多样(如基于@Controller注解的类、实现了Controller接口的旧式类、HttpRequestHandler等),DispatcherServlet需要一种统一的方式来调用它们。HandlerAdapter屏蔽了不同Handler实现细节的差异,提供了统一的调用接口。常见的实现如RequestMappingHandlerAdapter(用于调用@RequestMapping注解的方法)。**
Controller/Handler(处理器/控制器)**:处理具体的请求。它接收DispatcherServlet通过HandlerAdapter转发的请求,处理用户输入(解析参数、表单、请求体等),调用服务层进行业务处理,并返回一个包含模型数据和逻辑视图名的ModelAndView对象(或其它类型的返回值,如ResponseEntity,String视图名等)。通常使用@Controller或@RestController注解标记。ModelAndView(模型与视图):封装处理结果,包含模型数据(
Model)和视图名称(View)。装载了模型数据和视图信息,作为 Handler 的处理结果,返回给 DispatcherServlet。
ViewResolver(视图解析器): 将
Controller返回的逻辑视图名解析为实际的View对象。Controller通常返回一个字符串(如"userList"或"redirect:/success"),这只是一个逻辑标识。ViewResolver根据配置的规则(如视图前缀、后缀)将这个逻辑名映射到具体的视图技术实现(如 JSP 文件/WEB-INF/views/userList.jsp, Thymeleaf 模板, FreeMarker 模板等)。常见的实现如InternalResourceViewResolver(用于 JSP/JSTL)。View(视图):负责渲染最终的响应内容(通常是 HTML)。
它使用
Model中的数据,结合特定的视图技术(JSP, Thymeleaf, FreeMarker, PDF, JSON 等)来生成具体的输出(HTML, JSON, XML, PDF 等),并将其写入 HTTP 响应流。DispatcherServlet将渲染任务委托给View对象。HandlerInterceptor(拦截器):在请求处理前后执行自定义逻辑(如日志记录、权限验证)。
ExceptionHandler(异常处理器):统一处理控制器抛出的异常。
MultipartResolver(文件上传解析器):处理文件上传请求。
Spring MVC 的工作原理
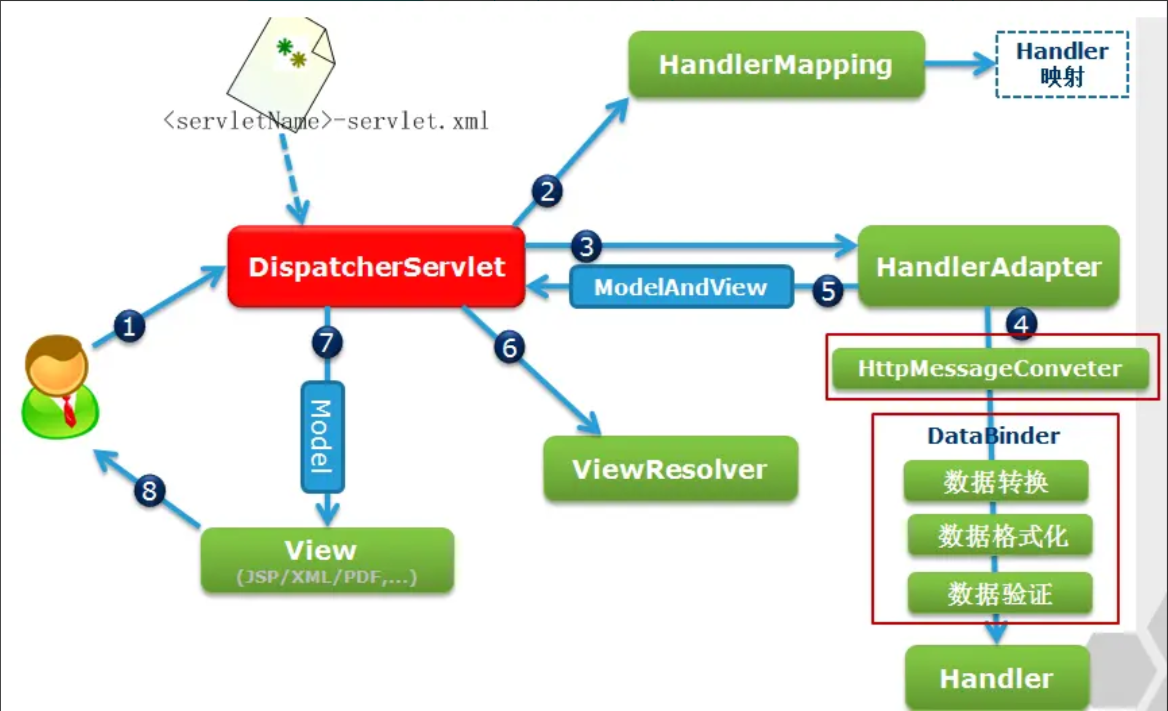
- 请求到达:用户发送 HTTP 请求到 Web 服务器。
DispatcherServlet接管:请求被配置好的DispatcherServlet捕获。- 查找
Handler:DispatcherServlet查询HandlerMapping,根据请求 URL 等信息找到对应的Handler(Controller 方法) 和拦截器链。 - 执行拦截器前置处理:如果配置了拦截器 (
HandlerInterceptor),执行其preHandle方法。 - 适配并执行
Handler:DispatcherServlet通过合适的HandlerAdapter调用找到的Handler(Controller 方法)。 Controller处理:Controller执行业务逻辑:- 处理请求参数、表单数据、请求体等。
- 调用 Service 层。
- 将结果数据放入
Model。 - 返回一个结果(逻辑视图名
String,ModelAndView,ResponseEntity等)。
- 执行拦截器后置处理:如果配置了拦截器,执行其
postHandle方法(此时Model已填充)。 - 解析视图:
DispatcherServlet将Controller返回的逻辑视图名交给ViewResolver解析,得到具体的View对象。 - 渲染视图:
DispatcherServlet调用View对象的render()方法,传入Model数据。View使用模型数据和特定技术生成响应内容(如 HTML)。 - 执行拦截器最终处理:如果配置了拦截器,执行其
afterCompletion方法(无论成功或异常)。 - 返回响应: 生成的响应内容通过
DispatcherServlet返回给 Web 服务器,最终发送给客户端。
事务
Spring 事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,Spring 是无法提供事务功能的。Spring 只提供统一事务管理接口,具体实现都是由各数据库自己实现,数据库事务的提交和回滚是通过数据库自己的事务机制实现。
Spring 管理事务的方式有几种?
Spring 管理事务的方式主要分为两大类:声明式事务和编程式事务。声明式事务是首选和主流的方式,因为它更简洁、非侵入性且符合 Spring 的 AOP 理念。编程式事务则提供了更细粒度的控制,但代码侵入性强。
声明式事务(Declarative Transaction Management)
通过 AOP 实现事务管理,将事务逻辑与业务代码分离,降低耦合度。其本质是通过 AOP 功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前启动一个事务,在目标方法执行完之后根据执行情况提交或者回滚事务。
实现方式
基于
@Transactional注解(最常用)原理:利用 Spring AOP 动态代理在方法执行前后添加事务逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 启用事务注解支持
public class AppConfig {
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource); // 配置事务管理器
}
}
public class UserService {
public void updateUser(User user) {
// 业务逻辑(自动被事务包裹)
}
}
基于 XML 配置(旧项目常用)
在 XML 中定义事务规则,无需修改源码:
<!-- 配置事务管理器 --> <bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource"/> </bean> <!-- 定义事务规则 --> <tx:advice id="txAdvice" transaction-manager="txManager"> <tx:attributes> <tx:method name="update*" propagation="REQUIRED" rollback-for="Exception"/> <tx:method name="get*" read-only="true"/> </tx:attributes> </tx:advice> <!-- 通过 AOP 应用事务 --> <aop:config> <aop:advisor advice-ref="txAdvice" pointcut="execution(* com.example.service.*.*(..))"/> </aop:config>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2. 编程式事务(Programmatic Transaction Management)
通过编写代码直接管理事务的生命周期,灵活性高但代码侵入性强。编程式事务可以使用 TransactionTemplate 和 PlatformTransactionManager 来实现,需要显式执行事务。允许我们在代码中直接控制事务的边界,通过编程方式明确指定事务的开始、提交和回滚。
实现方式
- **使用 `TransactionTemplate`(推荐编程式方案)**
```java
@Service
public class OrderService {
@Autowired
private TransactionTemplate transactionTemplate;
public void createOrder(Order order) {
transactionTemplate.execute(status -> {
try {
orderDao.save(order);
inventoryService.deductStock(order.getProductId());
return null; // 返回结果(可自定义)
} catch (Exception e) {
status.setRollbackOnly(); // 标记回滚
throw e;
}
});
}
}
直接使用
PlatformTransactionManager(底层 API)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class PaymentService {
private PlatformTransactionManager txManager;
public void processPayment() {
TransactionDefinition def = new DefaultTransactionDefinition();
TransactionStatus status = txManager.getTransaction(def);
try {
paymentDao.executePayment();
txManager.commit(status); // 提交事务
} catch (Exception e) {
txManager.rollback(status); // 回滚事务
throw e;
}
}
}
Spring 事务的隔离级别
Spring 事务的隔离级别(Isolation Level)是数据库事务处理中的核心概念,用于控制多个并发事务对同一数据的访问规则,解决脏读、不可重复读、幻读等问题。Spring 通过 @Transactional 注解的 isolation 属性支持标准的事务隔离级别,其底层依赖于数据库的实现。
1 |
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) | 适用场景 | 性能影响 |
|---|---|---|---|---|---|
READ_UNCOMMITTED (读未提交) |
❌ 可能发生 | ❌ 可能发生 | ❌ 可能发生 | 极低并发场景(几乎不用) | 最高 |
READ_COMMITTED (读已提交) |
✅ 禁止 | ❌ 可能发生 | ❌ 可能发生 | 多数数据库默认级别(如 Oracle) | 较高 |
REPEATABLE_READ (可重复读) |
✅ 禁止 | ✅ 禁止 | ❌ 可能发生 | MySQL InnoDB 的默认级别 | 中等 |
SERIALIZABLE (串行化) |
✅ 禁止 | ✅ 禁止 | ✅ 禁止 | 高一致性要求场景(如金融交易) | 最低 |
DEFAULT (默认) |
- | - | - | 使用数据库的默认隔离级别(推荐) | 依赖数据库 |
READ_UNCOMMITTED(读未提交)问题:事务能读取其他事务未提交的数据(脏读)。
场景:
1
2
3
4
5-- 事务A
UPDATE account SET balance = 1000 WHERE id = 1; -- 未提交
-- 事务B(READ_UNCOMMITTED)
SELECT balance FROM account WHERE id = 1; -- 读到1000(脏数据)风险:事务A若回滚,事务B读到的数据就是无效的。
READ_COMMITTED(读已提交)解决:禁止脏读(只读已提交数据)。
遗留问题:不可重复读(同一事务内多次读同一数据结果不同)。
场景:
1
2
3
4
5
6
7
8
9-- 事务B(第一次查询)
SELECT balance FROM account WHERE id = 1; -- 返回1000
-- 事务A提交更新
UPDATE account SET balance = 900 WHERE id = 1;
COMMIT;
-- 事务B(第二次查询)
SELECT balance FROM account WHERE id = 1; -- 返回900(两次读取结果不一致!)
REPEATABLE_READ(可重复读)解决:禁止脏读、不可重复读。
遗留问题:幻读(同一查询条件返回的行数变化)。
场景(MySQL InnoDB 通过 MVCC 解决了幻读):
1
2
3
4
5
6
7
8
9-- 事务B(第一次查询)
SELECT COUNT(*) FROM orders WHERE user_id = 1; -- 返回5条
-- 事务A插入新订单并提交
INSERT INTO orders(user_id) VALUES (1);
COMMIT;
-- 事务B(第二次查询)
SELECT COUNT(*) FROM orders WHERE user_id = 1; -- 仍返回5条(避免幻读)
SERIALIZABLE(串行化)解决:所有并发问题(通过强制事务串行执行)。
代价:性能严重下降(类似表级锁)。
场景:
1
2
3
4
5-- 事务B执行查询(自动加共享锁)
SELECT * FROM account WHERE id = 1;
-- 事务A尝试更新(被阻塞,直到事务B结束)
UPDATE account SET balance = 800 WHERE id = 1;
Spring 事务的传播机制
Spring 事务的传播机制定义了 当一个事务方法被另一个事务方法调用时,如何管理事务的创建、嵌套和合并。这是 Spring 事务管理中最复杂且强大的特性之一,通过 @Transactional(propagation = Propagation.XXX) 枚举类提供 7 种传播行为。
| 传播行为 | 是否创建新事务 | 当前无事务时 | 异常影响范围 | 应用场景 |
|---|---|---|---|---|
REQUIRED |
否(加入现有) | 创建新事务 | 整个事务回滚 | 常规业务逻辑 |
SUPPORTS |
否 | 非事务执行 | 无事务,异常不触发回滚 | 查询操作 |
MANDATORY |
否 | 抛出异常 | 整个事务回滚 | 强制要求事务的敏感操作 |
REQUIRES_NEW |
是 | 创建新事务 | 仅影响当前事务 | 日志记录、独立子操作 |
NOT_SUPPORTED |
否 | 非事务执行 | 无事务,异常不触发回滚 | 非事务的性能敏感操作 |
NEVER |
否 | 非事务执行 | 存在事务时抛出异常 | 禁止事务的操作 |
NESTED |
否(嵌套事务) | 创建新事务(同 REQUIRED) |
嵌套事务回滚不影响外层,外层回滚嵌套也回滚 | 子操作可独立回滚的场景 |
REQUIRED(默认)规则:
- 若当前存在事务,则加入该事务;
- 若不存在事务,则新建一个事务。
场景:
1
2
3
4
5
6
7
public void methodA() {
methodB(); // 加入 methodA 的事务
}
public void methodB() { ... }用途:最常用的传播行为(如订单创建+库存扣减需在同一事务)。
SUPPORTS规则:
- 若当前存在事务,则加入;
- 若不存在事务,则以非事务方式执行。
场景:查询方法(支持事务但不强制)。
1
2
public User getUserById(Long id) { ... }应用场景:查询方法(无需事务,但可参与外层事务)。
MANDATORY规则:
- 若当前存在事务,则加入;
- 若不存在事务,则抛出异常(
IllegalTransactionStateException)。
场景:强制要求调用方必须开启事务(如资金操作)。
1
2
3
4
5
6
7
8
9
10
11
12
13
public void methodA() {
methodB(); // 正确:B 加入 A 的事务
}
public void methodC() {
methodB(); // 错误:抛出异常,因为 C 无事务
}
public void methodB() {
// 必须在事务中执行
}
REQUIRES_NEW规则:
- 无论当前是否存在事务,都新建一个独立事务;
- 原事务(若有)被挂起,新事务执行完毕后再恢复。
场景:日志记录(即使主事务失败,日志仍需提交)。
1
2
3
4
5
6
7
8
9
10
11
12
13
public void methodA() {
try {
methodB(); // B 创建新事务,A 的事务挂起
} catch (Exception e) {
// B 的异常不影响 A 的事务
}
}
public void methodB() {
// 独立事务
}
NOT_SUPPORTED规则:
- 以非事务方式执行;
- 若当前存在事务,则挂起该事务。
场景:执行耗时操作(如文件处理),避免长事务阻塞。
1
2
3
4
5
6
7
8
9
public void methodA() {
methodB(); // A 的事务挂起,B 以非事务方式执行
}
public void methodB() {
// 非事务执行
}
NEVER规则:
- 强制要求不在事务中执行;
- 若当前存在事务,则抛出异常。
场景:与事务不兼容的操作(如某些外部 API 调用)。
1
2
3
4
5
6
7
8
9
10
11
12
13public void methodA() {
methodB(); // 正确:A 无事务
}
public void methodC() {
methodB(); // 错误:抛出异常,因为 C 有事务
}
public void methodB() {
// 禁止在事务中执行
}
NESTED规则:
- 若当前存在事务,则在嵌套事务中执行(使用保存点 Savepoint);
- 若不存在事务,则同
REQUIRED(新建事务)。
特点:
- 嵌套事务回滚不影响主事务(除非主事务提交);
- 主事务回滚会导致嵌套事务一起回滚。
场景:复杂业务中的子操作(如订单拆分子订单,子订单失败不影响主订单)。
1
2
3
4
5
6
7
8
9
10
11
12
13
public void methodA() {
try {
methodB(); // 嵌套事务
} catch (Exception e) {
// B 回滚,但 A 可以继续执行或提交
}
}
public void methodB() {
// 嵌套事务,使用保存点
}
spring 声明式事务在哪些情况下会失效?
方法的访问权限问题
若事务方法的访问权限是
private、protected或者默认的(包级私有),或者final/static方法,事务就会失效。因为Spring 默认使用基于 JDK 的动态代理(当接口存在时)或基于 CGLIB 的代理(当只有类时)来实现事务。同类内部方法调用
1
2
3
4
5
6
7
8
9
10
11
12
13
public class UserService {
public void saveUser(User user) {
// 非事务方法调用事务方法
this.updateUser(user);
}
public void updateUser(User user) {
// 数据库操作
}
}原因:Spring 事务基于 AOP 代理,内部调用不走代理。
解决办法:
借助
ApplicationContext来获取代理对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class UserService {
private ApplicationContext context;
public void saveUser(User user) {
UserService proxy = context.getBean(UserService.class);
proxy.updateUser(user);
}
public void updateUser(User user) {
// 数据库操作
}
}通过构造函数注入自身代理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class UserService {
private final UserService self;
public UserService(UserService self) {
this.self = self;
}
public void saveUser(User user) {
self.updateUser(user);
}
public void updateUser(User user) {
// 数据库操作
}
}
未被 Spring 容器管理
1
2
3
4
5// ❌ 未加 @Service 注解
public class ExternalService {
public void process() { ... }
}原因:非 Spring Bean 无法被代理。
解决:确保类被注解标记(@Component,@Service等)。注解未被正确扫描
若
@Transactional注解所在的类没有被 Spring 组件扫描到,或者没有启用事务支持,事务就会失效。解决办法:
确保配置了@EnableTransactionManagement注解:1
2
3
4
5
6
public class AppConfig {
// 配置类
}异常类型不匹配
1
2
3
4
5
public void update() throws IOException {
jdbcTemplate.update(...); // 抛 SQLException(RuntimeException 子类)
throw new IOException(); // 非 RuntimeException
}原因:若事务方法抛出的异常不在
@Transactional注解的rollbackFor( 用来指定能够触发事务回滚的异常类型 ) 范围内,事务将不会回滚。Spring 默认抛出未检查 unchecked 异常(继承自 RuntimeException 的异常)或者 Error 才回滚事务,其他异常不会触发回滚事务。解决:显式指定回滚异常
1
异常被捕获未抛出
1
2
3
4
5
6
7
8
public void update() {
try {
jdbcTemplate.update(...); // 抛异常
} catch (DataAccessException e) {
// 吞掉异常 → 事务不会回滚!
}
}解决:在 catch 中抛出
RuntimeException或手动回滚:1
2
3
4catch (Exception e) {
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
throw new BusinessException(e);
}事务传播行为配置有误
要是事务传播行为配置成
PROPAGATION_SUPPORTS、PROPAGATION_NOT_SUPPORTED或者PROPAGATION_NEVER,在特定条件下事务会失效。1
2
3
4
public void doSomething() {
// 此方法不会在事务中执行
}解决办法:
依据业务需求,合理选择传播行为,像PROPAGATION_REQUIRED就是常用的选择。1
2
3
4
public void doSomething() {
// 会加入当前事务或者创建新事务
}多线程环境问题
在多线程环境中,由于每个线程拥有独立的事务上下文,子线程的事务不会影响主线程。
1
2
3
4
5
6
7
8
9
10
11
12
public void parentMethod() {
new Thread(() -> {
// 子线程中的事务与主线程无关
childMethod();
}).start();
}
public void childMethod() {
// 数据库操作
}解决办法: 尽量避免在多线程中使用事务,或者采用其他方式来保证数据一致性。
 微信
微信 支付宝
支付宝

